
仿真,正在成为具身智能竞争的新赛场
早览国事 | 2026-06-06 16:16:48

过去几年,全球人工智能(AI)竞争的焦点集中在模型、算法和算力。大模型的快速突破,让GPU、CUDA、芯片成为产业关注的核心,也让算力基础设施自主可控成为广泛共识。
但当AI从数字世界走向物理世界,竞争的底层逻辑正在发生变化。
在数字世界中,AI处理的是文本、图像和视频;在物理世界中,机器人面对的是由材料、空间、设备、流程和安全约束共同构成的复杂现实系统。它不只是“理解世界”,更要与真实物理环境持续交互、在复杂场景中完成任务。这正是具身智能的挑战所在。
大语言模型答错一道题可以重新生成;机器人在真实场景中的一次错误动作,可能损坏设备、打断流程,甚至带来安全风险。AI一旦进入物理世界,试错成本就不再只是算力成本,而是时间、工程、运营和安全的综合代价。
因此,物理AI无法像大模型那样在真实世界中无限试错。它需要一个足够真实、可重复、可量化、可规模化的虚拟物理环境,在进入真实产业现场之前,完成训练、验证和评测。
这就是仿真。

如果说大模型时代最突出的依赖是算力,那么物理AI时代更深层、更隐蔽的依赖,正在转向仿真——而仿真之所以进一步取代算力成为底层瓶颈,关键在于数据问题发生了根本变化。
大模型的数据主要来自互联网文本、图像和视频;自动驾驶的数据主要来自车辆在真实道路上的采集;而具身智能需要的,是包含动作、接触、受力、材料、空间关系和任务结果的物理交互数据——这是一类前所未有的数据形态。
据光轮智能联合创始人兼总裁杨海波判断,2026年正在成为具身智能“数据规模化元年”。与自动驾驶相比,机器人面对的是更加开放的物理世界,需要处理更多样的场景、任务、物体和物理交互,且目前尚未形成成熟、规模化的本体回环数据。“具身智能的数据量需求,至少是自动驾驶的1000倍。”
单靠真实世界采集,难以支撑这样的数据需求。人类视频可以提供行为参考,却无法完整描述力学状态、接触变化和任务结果。仿真合成数据把真实经验放入可控、可复现的物理环境中,规模化生成可用于训练和评测的物理交互数据。
换句话说,物理AI时代真正稀缺的,不是算力,而是一个能够持续生成数据、承载训练、完成评测、反哺迭代的仿真系统——这正是仿真被推上物理AI关键底座的根本原因。
物理AI发展的隐蔽瓶颈
仿真对外依赖度高于算力
早在工业时代,高端工业仿真软件和关键物理引擎主要由欧美企业和机构主导。美国的Ansys、法国的达索、德国的西门子等工业仿真平台,深度服务航空航天、汽车、能源等关键领域,并在底层技术、工程流程、标准体系和生态规则中形成长期优势。
进入物理AI时代,国际科技巨头又开始围绕物理引擎、机器人学习、仿真评测和开源生态持续布局。
英伟达收购PhysX,并将仿真能力与GPU、Omniverse、Isaac等生态深度绑定;谷歌DeepMind收购并开源MuJoCo,使其成为机器人强化学习的重要工具;丰田研究院长期主导Drake,面向高可信动力学、控制与规划;迪士尼研究院自研Kamino,聚焦复杂机械结构和高难度运动求解。
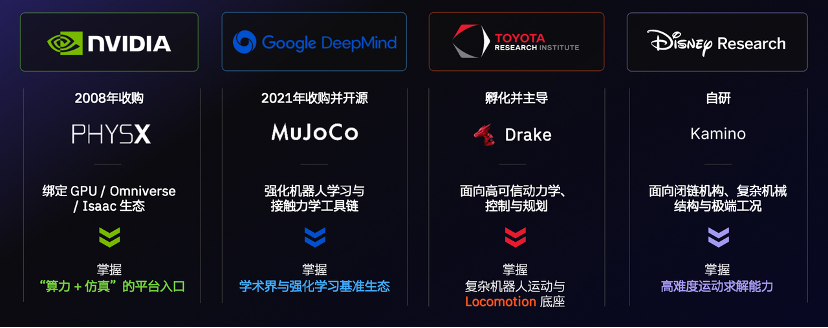
这些动作本质上争夺的是物理AI时代的基础设施入口:谁定义仿真环境和评测体系,谁就可能影响机器人如何学习、如何训练、如何被评测;谁进入底层生态,谁就有机会参与下一代物理AI基础设施的规则制定。
值得注意的是,与算力相比,仿真对外依赖的隐蔽性更高。
算力的“卡脖子”会直观体现在芯片供货、出口管制、海关单据上;而仿真的依赖则深嵌在物理引擎、求解器、数据格式、评测框架与开源生态之中——它不出现在新闻头条,却悄然决定着机器人产业的训练和评测的能力天花板。
一旦底层引擎、关键标准和评测体系在国外固化,国产具身智能产业将长期面对“模型能跑,但训练和评测环境受制于人”的结构性约束。
对于刚刚被列入国家未来产业重点方向的具身智能而言,仿真,正是这样一个必须正视,且时间窗口已经开始收窄的“卡脖子”环节。
光轮智能参与国际物理AI规则共建
2026年3月,光轮智能接受了英伟达、谷歌DeepMind和迪士尼研究院的联合邀请,加入国际开源GPU加速物理引擎Newton技术指导委员会(TSC),成为其中唯一来自中国的企业成员。
Newton的目标是面向下一代物理AI仿真需求,构建开放、统一、可扩展的物理仿真架构。其技术指导委员会负责核心技术路线、接口规范、生态治理和标准演进方向。光轮智能加入其中,意味着中国企业进到重要国际开源技术生态的决策机制,参与下一代仿真架构、技术路线与生态规则的共建。

支撑这一突破的,是光轮智能“求解—测量—生成”三位一体全栈自研仿真平台。求解负责在虚拟环境中还原力、碰撞、接触和形变,让仿真在物理上可信;测量负责把材料、接触、摩擦、形变等真实物理属性带入系统;生成则把这些物理规律规模化扩展为可训练、可评测、可复用的仿真世界。通俗地讲,就是先把物理规律算准,再把真实世界量准,最后规模化造出可用于训练和评测的虚拟世界。
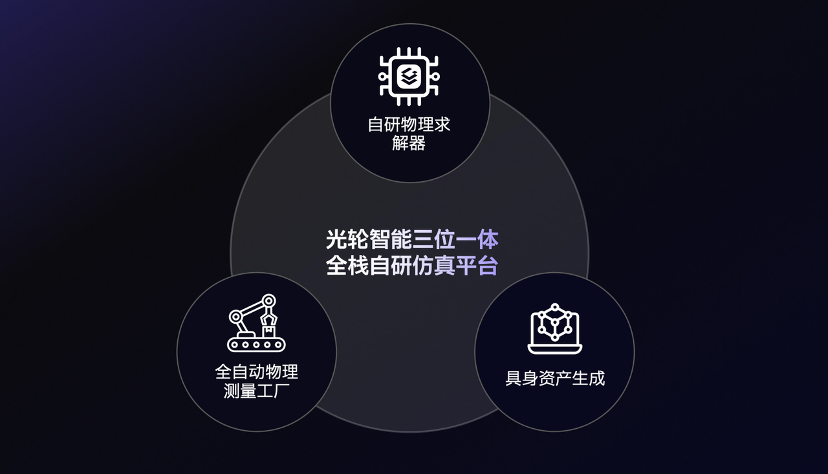
推动国产物理AI基础设施协同创新
在参与国际规则共建的同时,光轮智能也在国内推进物理AI基础设施的系统性建设。
在算力层面,光轮智能与摩尔线程达成合作,推动数据生成与仿真评测方案在国产算力环境中的适配和运行。在模型评测层面,光轮智能与通义千问围绕工业级仿真评测平台RoboFinals等方向推进共建,探索用可复现、可量化、可规模化的方式衡量具身智能模型的能力边界。
在标准与检测层面,围绕智能仿真平台、工业高质量数据集、具身智能数据质量、数据采集系统能力等方向,光轮智能联合全国信标委、工信部相关标委会等机构,牵头或参与制定20项国家、行业相关标准;与国家机器人检测和评定中心(总部)开展合作,围绕“真实+仿真”评测闭环、评测方法、评测流程与指标体系进行协同探索。作为全国首批具身智能行动计划数据领域唯一民企,光轮智能也在持续推动高质量具身智能数据集建设。
此外,对于物理AI数据与仿真基础设施而言,真正关键的不只是交付了多少数据,而是数据能否被不同客户、不同模型阶段和不同任务体系反复调用。光轮智能将这一能力概括为“数据复售率”,即单位小时的光轮数据能够服务多少个不同客户和任务需求。
杨海波介绍,光轮智能优质场景数据的复售率已经能够超过10倍。这意味着高质量具身数据不再只是一次性交付物,而是可以持续流通、持续增值的基础设施型资产。
可以说,以光轮智能为代表的中国企业不仅正在物理AI时代让具身行业具备更强的应用能力,也在底层标准、检测评测和基础设施体系上逐渐形成话语权。
这一次,中国企业不会只做追赶者,也正在成为规则共建者。
这场竞争,才刚刚开始。
责任编辑:马瑞琳